Voice recognition, the ability of computers to understand human speech, has exploded onto the scene. From Siri and Alexa to medical transcription and self-driving cars, its impact is undeniable. This exploration delves into the history, technology, applications, and ethical considerations surrounding this rapidly evolving field, examining its potential and its pitfalls.
We’ll trace its evolution from clunky early systems to the sophisticated algorithms powering today’s voice assistants, uncovering the magic behind acoustic modeling, language processing, and the incredible feats of decoding human speech. We’ll also tackle the challenges, like accuracy limitations and privacy concerns, and speculate on what the future holds for voice recognition.
History of Voice Recognition
Voice recognition, the ability of a machine to understand and interpret human speech, has a surprisingly long and fascinating history, evolving from rudimentary concepts to the sophisticated technology we use daily. Its journey reflects the broader progress in computing power, signal processing, and artificial intelligence. This evolution has been marked by periods of significant breakthroughs, followed by periods of slower progress, ultimately leading to the widespread adoption we see today.Early attempts at voice recognition date back to the mid-20th century, a time when the very idea seemed almost science fiction.
These early systems were incredibly limited, struggling with even simple vocabularies and exhibiting high error rates. The technological constraints of the time severely hampered their capabilities.
Early Voice Recognition Systems
Early voice recognition systems, developed primarily in the 1950s and 60s, relied on very basic acoustic analysis techniques. They typically worked with extremely limited vocabularies (often just a few digits or words) and were highly speaker-dependent, meaning they had to be trained on a specific individual’s voice. One notable example is Audrey, a system developed at Bell Labs in 1952, which could recognize digits spoken by a single speaker.
These systems relied heavily on simple pattern matching techniques, comparing the acoustic features of the input speech to pre-recorded templates. The limitations were significant: noisy environments, variations in pronunciation, and different speakers all resulted in significant errors. These systems were far from practical for widespread use, but they laid the groundwork for future advancements.
Significant Milestones and Breakthroughs
Several key milestones propelled the field forward. The development of dynamic time warping (DTW) in the 1970s provided a more robust method for comparing speech patterns, allowing for variations in speaking rate and pronunciation. The introduction of hidden Markov models (HMMs) in the 1980s revolutionized speech recognition, providing a statistically-based framework for modeling the complex patterns in speech. This significantly improved accuracy and robustness.
The availability of increasingly powerful computers and the development of sophisticated algorithms further fueled progress. The 1990s saw the emergence of large vocabulary continuous speech recognition (LVCSR), enabling systems to handle natural, continuous speech rather than isolated words. This was a critical step towards practical applications.
Comparison of Early and Modern Approaches
Early systems were primarily based on template matching, were highly speaker-dependent, and had extremely limited vocabularies. They were fragile and prone to errors in the face of variations in speaking style or background noise. Modern systems, in contrast, leverage powerful statistical models like HMMs and deep learning techniques, such as recurrent neural networks (RNNs) and transformers. These models can handle large vocabularies, adapt to different speakers (speaker-independent), and exhibit significantly improved robustness to noise and variations in pronunciation.
The use of deep learning, in particular, has led to a dramatic improvement in accuracy over the past decade, making voice recognition technology a ubiquitous part of our lives. For example, early systems might only recognize a few isolated digits with high error rates, while modern systems can transcribe hours of continuous speech with remarkable accuracy.
How Voice Recognition Works
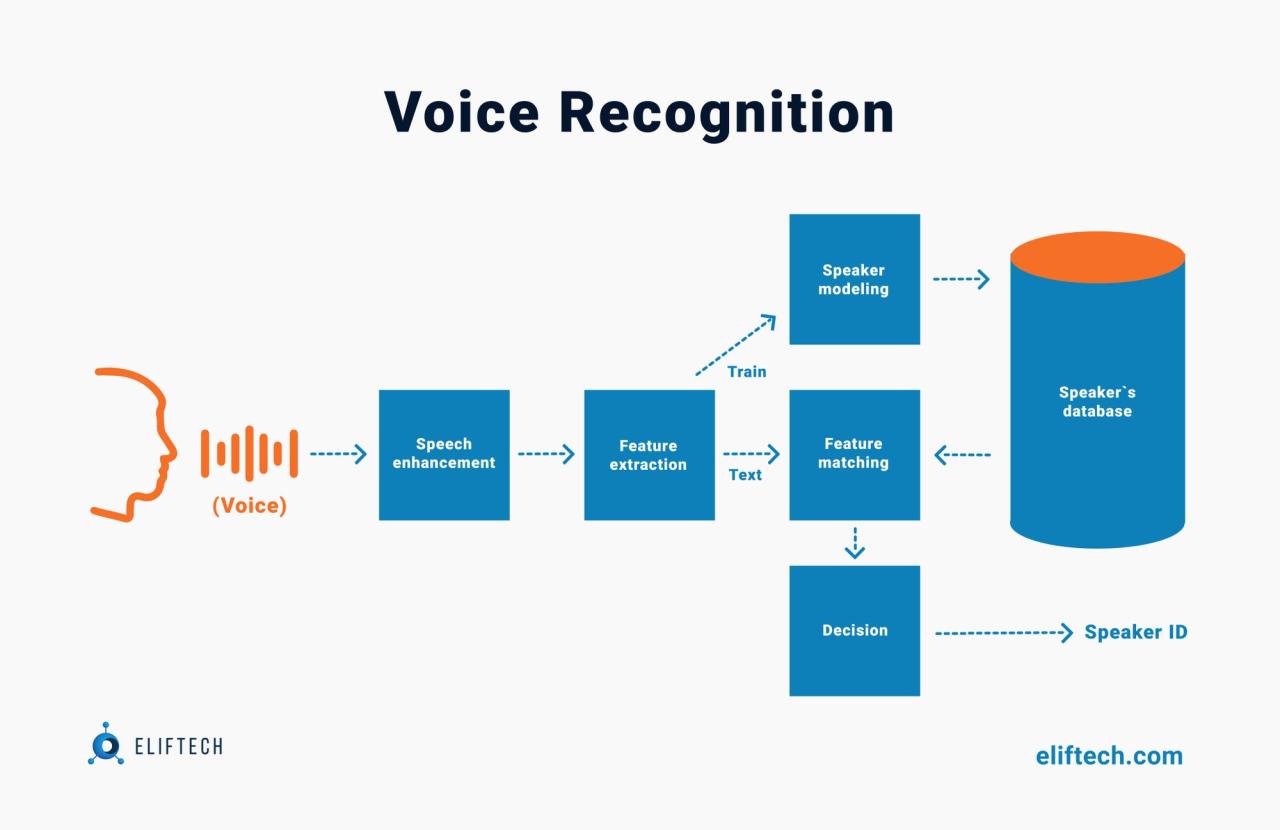
Voice recognition, or automatic speech recognition (ASR), is a complex process that mimics human hearing and understanding. It transforms spoken language into text, a seemingly simple task that actually involves sophisticated algorithms and multiple processing stages. Think of it as a digital ear and brain working together to decipher the nuances of human speech.
At its core, voice recognition systems break down the speech signal into smaller units, analyze these units to identify patterns, and then use these patterns to determine the most likely words or phrases spoken. This process involves several key components working in concert: a microphone captures the audio, signal processing cleans up the audio, acoustic modeling converts sound into phonetic units, language modeling predicts word sequences, and a decoder combines these predictions to produce the final text output.
The whole system is trained on massive datasets of speech and text to achieve accuracy.
Acoustic Modeling
Acoustic modeling is the process of converting the raw audio signal into a sequence of phonetic units. This involves analyzing the acoustic features of the speech signal, such as frequency, intensity, and duration, and mapping them to phonetic sounds. Think of it like translating the sounds of speech into a code that the computer can understand. Hidden Markov Models (HMMs) and deep neural networks (DNNs), particularly recurrent neural networks (RNNs) and convolutional neural networks (CNNs), are commonly used algorithms for acoustic modeling.
These models learn the statistical relationships between the acoustic features and the corresponding phonetic units through extensive training on large speech corpora. For example, a DNN might learn to recognize the characteristic frequencies and intensities associated with the sound /p/ in different contexts.
Language Modeling
While acoustic modeling focuses on the sounds, language modeling focuses on the meaning and structure of the language. It predicts the probability of a sequence of words based on the grammar and vocabulary of the language. This helps the system choose the most likely word sequence given the phonetic units provided by the acoustic model. N-gram models, which predict the probability of a word based on the preceding N-1 words, are a classic example.
More advanced techniques like recurrent neural networks (RNNs), especially Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), are increasingly used because they can capture long-range dependencies in language. For instance, a language model might predict “the cat sat on the mat” as more likely than “the cat sat on the map,” even if the acoustic model provides similar phonetic sequences for both.
Decoding
Decoding is the final stage, where the system combines the outputs of the acoustic and language models to produce the final text transcription. It’s essentially a search problem, finding the most likely sequence of words given the phonetic probabilities from the acoustic model and the word sequence probabilities from the language model. The Viterbi algorithm, a dynamic programming algorithm, is a common decoding technique.
However, more sophisticated techniques like beam search are often used to efficiently explore the search space and find the optimal sequence. The decoder acts like a judge, weighing the evidence from the acoustic and language models to produce the most plausible text. For example, if the acoustic model is slightly uncertain between “to” and “two,” the language model might favor “to” based on the surrounding words, leading to a more accurate transcription.
Applications of Voice Recognition
Voice recognition technology, once a futuristic fantasy, has seamlessly integrated into our daily lives. Its applications span numerous industries, revolutionizing how we interact with technology and each other. From simple commands to complex data analysis, voice recognition’s impact is undeniable and continues to grow exponentially. This section will explore the diverse applications of voice recognition across several key sectors, highlighting both the advantages and challenges.
Voice Recognition in Consumer Electronics
The consumer electronics market is a major beneficiary of voice recognition advancements. Smart speakers, like Amazon’s Alexa and Google Home, exemplify this. These devices allow users to control music playback, set alarms, make calls, and access information hands-free. Smartphones also heavily leverage voice recognition for tasks such as voice-to-text messaging, voice search, and hands-free calling. The convenience and accessibility offered by voice control have significantly broadened the appeal of these devices to a wider demographic, particularly those with disabilities or limited dexterity.
Voice Recognition in Healthcare
In healthcare, voice recognition plays a crucial role in improving efficiency and accuracy. Physicians use dictation software to transcribe patient notes and medical reports, saving valuable time and reducing administrative burdens. Voice-activated systems also assist in managing patient records, ordering medications, and controlling medical equipment. Furthermore, voice interfaces are being developed for patients with limited mobility, allowing them to interact with their medical devices and caregivers more easily.
The potential for reducing medical errors through automated transcription and improved patient communication is substantial.
Voice Recognition in the Automotive Sector
The automotive industry is rapidly adopting voice recognition technology to enhance driver safety and convenience. In-car voice assistants, similar to those in smartphones, allow drivers to make calls, navigate using GPS, control music, and send messages without taking their hands off the wheel or their eyes off the road. This technology contributes significantly to reducing distracted driving and improving road safety.
Voice recognition tech is blowing up, right? It’s getting used in everything from phones to cars. Imagine using voice commands to design complex structures in a CAD program – that’s the kind of seamless integration we’re heading towards. Think of the time saved! The future of voice recognition is looking pretty sweet.
Advanced systems are also being developed for hands-free vehicle control and automated driving features. The integration of voice recognition into the automotive landscape promises to transform the driving experience.
| Application | Industry | Benefits | Challenges |
|---|---|---|---|
| Smart speakers (e.g., Alexa, Google Home) | Consumer Electronics | Hands-free control, convenience, accessibility | Privacy concerns, accuracy issues in noisy environments, limited understanding of complex commands |
| Medical dictation and record keeping | Healthcare | Increased efficiency, reduced administrative burden, improved accuracy | Maintaining data security and privacy, ensuring accuracy in complex medical terminology, high initial investment costs |
| In-car voice assistants | Automotive | Improved driver safety, enhanced convenience, hands-free control | Accuracy in noisy environments, integration with various vehicle systems, potential for driver distraction if not properly designed |
Accuracy and Limitations of Voice Recognition
Voice recognition technology, while incredibly advanced, isn’t perfect. Its accuracy is affected by a complex interplay of factors, and understanding these limitations is crucial for realistic expectations and effective application. This section will explore the key factors influencing accuracy, common errors, and techniques used to improve performance.
Several factors significantly impact the accuracy of voice recognition systems. These range from the inherent variability in human speech to the complexities of processing audio signals. Noise, accents, speech impediments, and even the microphone quality all play a role in how well a system transcribes spoken words. Furthermore, the size and quality of the training data used to build the recognition model heavily influence its performance.
A model trained on a diverse range of voices and accents will generally be more robust than one trained on a limited dataset.
Factors Affecting Accuracy
The accuracy of voice recognition systems is a multifaceted issue. Several key factors contribute to both successes and failures in transcription. These factors can be broadly categorized as speaker-related, environment-related, and system-related.
- Speaker Characteristics: Accents, speech rate, clarity of pronunciation, and the presence of any speech impediments all affect accuracy. A system trained primarily on clear, standard pronunciation might struggle with heavily accented speech or someone with a lisp.
- Environmental Factors: Background noise (traffic, conversations, music), reverberation (echo), and microphone quality significantly impact the quality of the audio input. A noisy environment can lead to many misinterpretations.
- System Limitations: The size and quality of the training data, the sophistication of the algorithms used, and the system’s ability to handle variations in speech are all critical system-related factors. A system trained on a limited vocabulary might struggle with uncommon words or technical jargon.
Common Errors and Challenges
Despite advancements, voice recognition systems still make mistakes. Understanding these common errors is vital for managing expectations and improving system design.
- Word Confusion: Similar-sounding words (e.g., “there” and “their”) are frequently confused. This is particularly challenging when context is insufficient to disambiguate.
- Background Noise Interference: High levels of background noise often lead to insertions, deletions, and substitutions of words or phrases.
- Accent and Dialect Variation: Systems trained on specific accents may struggle with speakers having different accents or dialects.
- Speech Rate and Clarity: Very fast or mumbled speech can be difficult for systems to process accurately.
- Uncommon Words and Jargon: Systems may not recognize words or phrases outside their training data.
Techniques for Improving Accuracy, Voice recognition
Researchers continuously work to improve the robustness and accuracy of voice recognition systems. Several techniques are employed to address the limitations discussed above.
- Improved Acoustic Modeling: Advanced acoustic models utilize deep learning techniques to better capture the nuances of human speech, improving the system’s ability to handle variations in pronunciation and background noise.
- Advanced Language Modeling: Sophisticated language models use contextual information to predict the most likely sequence of words, reducing the likelihood of errors caused by word confusion.
- Data Augmentation: Expanding the training data by artificially creating variations (adding noise, changing speech rate) makes the system more robust to real-world conditions.
- Speaker Adaptation: Techniques allow the system to adapt to individual speakers’ voices, improving accuracy for regular users.
- Noise Reduction Techniques: Sophisticated algorithms are used to filter out background noise and improve the signal-to-noise ratio of the audio input.
Voice Recognition and Privacy Concerns
The increasing prevalence of voice recognition technology raises significant privacy concerns. Our voices, containing unique characteristics and often revealing personal information, are now routinely collected and analyzed by various applications and services. Understanding these implications and exploring effective privacy-preserving methods is crucial for responsible development and deployment of this technology.Voice data collected by voice recognition systems can be used to identify individuals, infer sensitive information about their health, location, and social interactions, and even be used to create highly realistic voice clones.
This information can be exploited for various malicious purposes, including identity theft, targeted advertising, and even blackmail. The sheer volume of data collected and the potential for unintended or malicious use represent serious risks to individual privacy.
Data Collection and Use Practices
Voice recognition systems typically collect audio recordings of users’ speech. This data is often stored on servers controlled by the technology providers, raising concerns about data breaches and unauthorized access. Furthermore, the metadata associated with voice data, such as timestamps, location information, and associated user accounts, can further compromise privacy. Many services also use this data to improve the accuracy of their voice recognition models, often without explicit and informed consent from users.
For example, a smart speaker recording a conversation in a home could inadvertently capture sensitive information like medical diagnoses or financial details. The lack of transparency about how this data is used and protected further exacerbates these concerns.
Methods for Protecting User Privacy
Several methods can be employed to mitigate privacy risks associated with voice recognition. Differential privacy techniques, for example, add carefully calibrated noise to the data to prevent the identification of individual users while still allowing for the development of accurate voice recognition models. Homomorphic encryption allows for computation on encrypted data, meaning that sensitive voice data can be processed without being decrypted, thereby safeguarding privacy.
Furthermore, federated learning enables model training on decentralized data, reducing the need to collect and centralize large amounts of voice data. Finally, strong data encryption both in transit and at rest is crucial to prevent unauthorized access to voice data. Transparency regarding data collection and use practices, coupled with strong user controls, is also essential for building trust and protecting user privacy.
Data Security and Anonymization Approaches
Different approaches to data security and anonymization exist, each with its own strengths and weaknesses. Data minimization involves collecting only the minimum amount of data necessary for the intended purpose. Data masking replaces sensitive information with non-sensitive substitutes, while pseudonymization replaces identifying information with pseudonyms. However, these techniques are not foolproof and can be circumvented with sophisticated attacks.
For example, sophisticated re-identification attacks can link anonymized data back to individuals. In contrast, strong encryption and secure storage practices represent a more robust approach, offering better protection against unauthorized access and data breaches. The choice of approach depends on the specific context, considering the level of risk and the trade-off between privacy and utility. For instance, a healthcare application might prioritize strong encryption and anonymization techniques over simpler methods due to the sensitive nature of medical information.
The Future of Voice Recognition

Voice recognition technology is rapidly evolving, poised to become even more integrated into our daily lives. We’re moving beyond simple commands and toward a future where nuanced conversations and complex tasks are handled seamlessly through voice interaction. This evolution will be driven by advancements in several key areas, leading to a wider range of applications and a more intuitive user experience.The next decade will likely witness significant improvements in both speech synthesis and natural language understanding (NLU).
These two pillars are crucial for creating truly natural and effective voice interactions. Current limitations in accurately interpreting accents, colloquialisms, and background noise will be addressed through more sophisticated algorithms and increased computational power. The result will be voice recognition systems that are more robust, adaptable, and capable of understanding the subtleties of human language.
Advancements in Speech Synthesis
Significant advancements are expected in the realism and expressiveness of synthetic speech. Current text-to-speech (TTS) systems, while improving, still often sound robotic. Future systems will likely leverage deep learning models trained on vast datasets of human speech to generate more natural-sounding voices with varied intonation, emotion, and even regional accents. Imagine virtual assistants that can convey empathy or humor, enhancing the user experience beyond simple task completion.
This could involve the development of more personalized voices, adapting to the user’s preferences and even mimicking the voices of loved ones. For example, a grieving individual might use a voice assistant with a synthesized voice mimicking their deceased relative.
Advancements in Natural Language Understanding
Natural Language Understanding (NLU) is the key to unlocking more complex voice interactions. Current systems struggle with understanding context, ambiguity, and nuanced language. Future advancements will likely focus on improving contextual awareness, enabling systems to understand the intent behind user requests even when expressed in less-than-perfect grammar or with incomplete information. This will involve incorporating more sophisticated knowledge graphs and reasoning capabilities, allowing voice assistants to infer meaning and respond more intelligently.
For instance, a system could understand the request “remind me to buy milk when I’m near the store” even if the user hasn’t explicitly specified a location or time. We can also expect to see systems that better understand and respond to emotions expressed in voice.
Potential New Applications of Voice Recognition
The coming decade will likely see voice recognition integrated into a much broader range of applications. While virtual assistants and voice search are already established, future applications will push the boundaries of what’s possible.The importance of these new applications lies in their potential to improve accessibility, efficiency, and overall user experience across various sectors. The following list showcases a few potential areas of significant growth.
- Advanced Healthcare: Voice-activated medical record systems, personalized medication reminders, and remote patient monitoring using voice analysis to detect changes in health conditions.
- Enhanced Education: Personalized tutoring systems that adapt to individual learning styles, voice-controlled interactive textbooks, and automated essay grading systems.
- Immersive Gaming: More natural and intuitive voice control for gaming characters and environments, allowing for richer and more engaging gameplay experiences.
- Smart Home Integration: Seamless voice control of all aspects of the smart home, from lighting and temperature to security systems and appliance operation, creating a truly integrated and personalized living environment.
- Improved Accessibility for People with Disabilities: Voice-controlled assistive technologies tailored to specific needs, empowering individuals with various disabilities to navigate their daily lives more independently.
Voice Recognition in Different Languages

Developing voice recognition systems is a complex undertaking, and the challenges increase exponentially when dealing with the world’s diverse languages. The accuracy and effectiveness of these systems are heavily influenced by the linguistic characteristics of the target language, making a one-size-fits-all approach impossible. Factors such as phoneme inventory, pronunciation variability, accent diversity, and the availability of large, high-quality datasets significantly impact the performance of voice recognition technology.The impact of language diversity on voice recognition systems is profound.
Languages with simpler phonetic structures and readily available data tend to have more accurate and robust voice recognition systems. Conversely, languages with complex phonologies, significant regional variations, or limited digital resources often lag behind. This disparity in performance highlights the need for targeted research and development efforts to address the unique challenges posed by each language. The resulting uneven distribution of advanced voice recognition technology can exacerbate existing inequalities in access to technology and information.
Challenges of Cross-Linguistic Voice Recognition
The development of voice recognition systems for different languages faces a unique set of hurdles. These challenges are multifaceted and often intertwined, making the process significantly more complex than simply translating existing systems. One major challenge is the sheer variability in phonetic inventories – the sounds a language uses. Languages like English have a relatively large and complex inventory of phonemes, while others have a smaller, simpler set.
This affects the accuracy of acoustic modeling, the process of converting sound waves into phonetic representations. Furthermore, the variability in pronunciation within a single language, due to accents, dialects, and individual speaking styles, poses a significant challenge. The availability of training data also plays a crucial role; languages with limited digital resources and less digitized speech data often struggle to achieve comparable accuracy.
Finally, morphological complexity – the way words are formed – can also impact the performance of language models. Languages with complex morphology, such as agglutinative languages, require more sophisticated linguistic processing techniques.
Language Prevalence and Associated Challenges
The following table summarizes the prevalence and challenges associated with voice recognition for selected languages. Prevalence is a broad indicator of the availability of voice recognition technology and related resources, while the challenges reflect the specific linguistic and technological hurdles faced in each case. Note that these are generalized observations, and specific challenges can vary considerably depending on the dialect and the specific voice recognition system used.
| Language | Prevalence | Challenges | Solutions |
|---|---|---|---|
| English | High | Accent variation, slang, fast speech | Large datasets, advanced acoustic modeling, dialect-specific training |
| Mandarin Chinese | High | Tonal variations, homophones | Advanced tonal modeling, robust disambiguation techniques |
| Spanish | Medium-High | Regional accents, fast speech | Dialect-specific training, improved phonetic modeling |
| Hindi | Medium | Complex phonology, limited datasets | Development of larger datasets, advanced phonetic modeling |
| Arabic | Low-Medium | Complex phonology, multiple dialects, limited datasets | Development of larger datasets, dialect-specific training, advanced morphological analysis |
Voice Recognition Hardware and Software
Voice recognition technology relies on a sophisticated interplay between specialized hardware and powerful software algorithms. Understanding these components is key to appreciating the capabilities and limitations of the systems we interact with daily. This section will explore the hardware and software building blocks that make voice recognition possible, contrasting different approaches and highlighting their respective strengths and weaknesses.
Hardware Components in Voice Recognition
The accuracy and efficiency of a voice recognition system are heavily influenced by the quality of its hardware. High-quality components ensure clear signal capture and processing, minimizing errors and improving overall performance. Key hardware components include microphones, analog-to-digital converters (ADCs), and digital signal processors (DSPs). Microphones capture the audio input, converting sound waves into electrical signals. The quality of the microphone significantly impacts the clarity of the audio signal; noise-canceling microphones are particularly important in noisy environments.
ADCs then transform these analog signals into digital data that can be processed by the system. Finally, DSPs are specialized processors optimized for handling digital signal processing tasks, such as filtering noise and enhancing the signal before it’s passed on for speech recognition. More advanced systems might incorporate multiple microphones for improved directionality and noise reduction, a technique often used in smartphones and smart speakers to isolate the user’s voice from background noise.
The processing power of the DSP also impacts the speed and accuracy of the recognition process; more powerful processors can handle more complex algorithms and larger datasets.
Software and Algorithms for Voice Recognition
The software component of voice recognition systems is arguably even more critical than the hardware. Sophisticated algorithms are responsible for transforming the digital audio data into meaningful text. These algorithms typically involve several stages: signal processing, acoustic modeling, language modeling, and decoding. Signal processing, as mentioned earlier, cleans and prepares the audio data. Acoustic modeling uses statistical models to map sounds to phonemes (basic units of sound in a language).
Language modeling incorporates grammatical rules and word probabilities to predict the most likely sequence of words. Finally, decoding combines the outputs of acoustic and language modeling to generate the final text transcription. Hidden Markov Models (HMMs) and deep neural networks (DNNs), particularly recurrent neural networks (RNNs) and long short-term memory (LSTM) networks, are commonly employed algorithms. DNNs, in particular, have driven significant improvements in accuracy in recent years due to their ability to learn complex patterns from large datasets.
The software also handles tasks such as vocabulary customization, speaker adaptation (adjusting to different voices), and integration with other applications.
Cloud-Based vs. On-Device Voice Recognition
The choice between cloud-based and on-device voice recognition involves a trade-off between accuracy, privacy, and resource consumption. Cloud-based systems leverage powerful servers to process audio data, often resulting in higher accuracy due to the availability of larger datasets and more sophisticated algorithms. However, this relies on a constant internet connection and raises privacy concerns regarding the transmission of personal voice data.
On-device recognition, conversely, processes audio locally on the device itself. This offers enhanced privacy, as no data is transmitted to external servers. However, on-device systems generally require more powerful hardware and may have lower accuracy due to limitations in processing power and dataset size. Apple’s Siri and Google Assistant, for instance, utilize a hybrid approach, combining on-device processing for quick responses with cloud-based processing for improved accuracy and functionality.
The best approach depends on the specific application and the priorities of the user or developer. For applications where privacy is paramount, on-device processing is preferred. For applications demanding high accuracy, cloud-based processing often provides better results.
Ethical Considerations of Voice Recognition
Voice recognition technology, while offering incredible advancements in convenience and accessibility, presents a complex array of ethical dilemmas. Its increasing integration into various aspects of our lives necessitates a careful examination of its potential societal impacts, particularly concerning surveillance, bias, and privacy. Failing to address these issues proactively could lead to significant harms and exacerbate existing inequalities.
The ethical implications of voice recognition are multifaceted and demand a nuanced understanding of its capabilities and limitations. The potential for misuse is substantial, and the development and deployment of this technology must prioritize responsible innovation to mitigate these risks. This requires a collaborative effort involving researchers, developers, policymakers, and the public to establish ethical guidelines and regulatory frameworks.
Surveillance and Security Applications of Voice Recognition
The use of voice recognition in surveillance and security raises significant ethical concerns. Law enforcement agencies and private entities are increasingly employing voice recognition systems to monitor conversations, identify individuals, and track movements. This raises questions about the balance between public safety and individual privacy. The potential for unwarranted surveillance and the chilling effect on free speech are major issues.
For example, the use of voice recognition in public spaces, without informed consent, could lead to the collection of sensitive personal information without an individual’s knowledge or permission. This raises concerns about potential abuses of power and the erosion of civil liberties. Clear legal frameworks and strict oversight are necessary to prevent the misuse of this technology for mass surveillance.
Bias and Discrimination in Voice Recognition Systems
Voice recognition systems are not immune to biases present in the data they are trained on. These systems often perform poorly for individuals with accents, dialects, or speech impairments, leading to discriminatory outcomes. For example, studies have shown that voice recognition systems are significantly less accurate for African American speakers compared to white speakers. This bias can have serious consequences, particularly in applications such as loan applications, hiring processes, and criminal justice.
Addressing this bias requires careful attention to data diversity and the development of more robust and inclusive algorithms. Moreover, ongoing monitoring and evaluation are crucial to identify and mitigate bias in existing systems.
Recommendations for Responsible Development and Deployment
Developing and deploying voice recognition technology responsibly requires a multi-pronged approach. Firstly, rigorous testing and evaluation are crucial to identify and mitigate biases in the system. This includes using diverse datasets representing a wide range of accents, dialects, and speech patterns. Secondly, transparency is essential. Users should be informed about how their voice data is collected, used, and protected.
Thirdly, robust data security measures are necessary to prevent unauthorized access and misuse of voice data. Fourthly, strong regulatory frameworks are needed to govern the use of voice recognition technology, particularly in sensitive applications such as law enforcement and healthcare. Finally, promoting public awareness and engagement in discussions about the ethical implications of this technology is vital for fostering responsible innovation.
These recommendations aim to ensure that voice recognition technology benefits society as a whole while minimizing potential harms.
Closure
Voice recognition is more than just a cool tech gadget; it’s reshaping how we interact with technology and the world around us. While challenges remain—especially regarding accuracy, privacy, and ethical implications—the potential benefits are enormous. As technology advances, we can expect even more seamless integration into our daily lives, transforming industries and revolutionizing how we communicate and access information.
The journey of voice recognition is far from over; it’s just getting started.
Quick FAQs
How does voice recognition handle accents and dialects?
Modern systems use vast datasets encompassing diverse accents and dialects to improve accuracy. However, heavily accented speech or uncommon dialects can still pose challenges.
Is my voice data secure when using voice assistants?
Data security varies greatly between providers. It’s crucial to read privacy policies and understand how companies handle and protect your voice data. Some offer encryption and anonymization techniques.
Can voice recognition be used offline?
Yes, but offline capabilities are often more limited than cloud-based systems. Offline systems require more processing power and storage on the device itself, and may have smaller vocabularies and lower accuracy.
What are the limitations of voice recognition in noisy environments?
Background noise significantly impacts accuracy. Advanced systems employ noise cancellation techniques, but very loud or complex sounds can still interfere with accurate transcription.
How is voice recognition used in healthcare?
In healthcare, voice recognition is used for medical transcription, generating patient reports, and controlling medical equipment hands-free, improving efficiency and reducing errors.